



![[FREE EBOOK] Strategic Vietnam IT Outsourcing: Optimizing Cost and Workforce Efficiency](https://vti.com.vn/wp-content/uploads/2023/08/cover-mockup_ebook-it-outsourcing-20230331111004-ynxdn-1.png)
What Is Predictive Maintenance?
Definition in a Manufacturing Context
Predictive maintenance (PdM) is a condition-based maintenance strategy that uses real-time equipment data — collected via sensors, PLCs, and machine signals — to detect early signs of failure before they cause unplanned downtime. Rather than following a fixed schedule or reacting to breakdowns after the fact, predictive maintenance tells you when a machine actually needs attention, based on how it is behaving right now.
In a factory setting, this means continuously monitoring variables like vibration, temperature, current draw, pressure, and acoustic emissions, then running that data through AI or statistical models trained to recognize the early signatures of component degradation. When integrated into a broader AI-driven factory architecture, PdM doesn’t just alert a technician — it can automatically adjust production schedules, trigger work orders in CMMS, and feed insights back into process optimization loops.
How It Differs from Traditional Maintenance Approaches
Most manufacturers have historically operated in one of two modes: reactive maintenance (fix it when it breaks) or preventive maintenance (service it on a calendar schedule). Both carry significant inefficiencies. Reactive maintenance leads to catastrophic failures, emergency labor costs, and cascading production losses. Preventive maintenance, while more structured, replaces components that still have useful life remaining — creating unnecessary spend and planned downtime that may not be warranted.
Predictive maintenance breaks this binary. It intervenes at the right moment — late enough to extract maximum asset life, early enough to avoid failure. In an AI-driven factory, this intervention is no longer a one-off action. It becomes part of a continuous, closed-loop system in which machine health data informs production decisions in near real time.
Why It Matters for High-Volume Production Environments
At scale, the economics are stark. A single hour of unplanned downtime on a high-volume automotive assembly line can cost anywhere from $50,000 to $500,000, depending on line complexity and downstream dependencies. In semiconductor fabrication, pharmaceutical packaging, or food processing, the cost may include regulatory exposure, product recalls, or customer penalty clauses on top of direct production loss.
For manufacturers running 24/7 or near-continuous operations, predictive maintenance is not a technology upgrade — it is a risk management imperative. And as factories evolve toward AI-driven operations, PdM is becoming one of the foundational data layers that makes everything else work.
Why Predictive Maintenance Is Becoming Critical in Modern Factories
Rising Cost of Unplanned Downtime
The true cost of downtime is routinely underestimated. Most finance teams capture direct labor and lost production output, but the full picture includes emergency parts procurement at premium prices, expedited freight, overtime maintenance labor, scrap and rework from interrupted processes, and reputational impact when delivery commitments are missed. Industry benchmarking consistently estimates that unplanned downtime costs industrial manufacturers tens of billions of dollars annually across sectors.
As production schedules become leaner and buffer stocks shrink under just-in-time principles, factories have progressively less tolerance for variability. Equipment reliability is no longer an operational concern — it is a direct input into supply chain performance and customer satisfaction.
Increasing Equipment Complexity
Modern manufacturing assets are fundamentally different from equipment of 20 years ago. CNC machining centers have 5-axis motion systems with thermal compensation algorithms. Injection molding machines manage dozens of interdependent process variables in real time. Collaborative robots and autonomous mobile platforms introduce failure modes that even experienced technicians may have little intuitive feel for.
As automation and AI density increase, so does interdependency. A single failed servo drive can halt an entire automated cell. A worn spindle bearing that would once have been caught during a routine walkthrough can go undetected until it destroys a $40,000 spindle — because that technician is now responsible for three times as many assets. In this environment, manual inspection alone is not a viable maintenance strategy.
Pressure to Improve OEE and Production Stability
Predictive maintenance directly attacks this gap. When equipment failures are caught early, unplanned stops are converted into planned maintenance windows, which can be scheduled to minimize production impact. Over time, this shift from unplanned to planned maintenance is one of the most reliable levers for sustainable OEE improvement — and in an AI-driven factory, that shift can be automated, orchestrated, and optimized across dozens of assets simultaneously.
Labor Shortages and Reduced Reliance on Manual Inspection
The skilled maintenance technician talent pool is shrinking. Experienced millwrights, electricians, and precision mechanics are aging out of the workforce faster than they are being replaced. The institutional knowledge they carry — the ability to “hear” a bad bearing or “feel” an imbalanced motor — is disappearing with them.
Predictive maintenance, at its best, encodes that expertise into data models. A vibration signature that a master technician would have recognized as early-stage bearing wear can now be flagged automatically, around the clock, across every monitored asset in the plant. This is not about replacing skilled labor — it is about amplifying its reach, preserving institutional knowledge in a scalable form, and ensuring that the humans in the loop are focused on decisions that require human judgment.
Predictive vs. Preventive vs. Reactive Maintenance
Understanding where predictive maintenance fits requires a clear view of the full strategy spectrum, their cost structures, and where each approach still makes sense.
| Dimension | Reactive (Run-to-Failure) | Preventive (Schedule-Based) | Predictive (Condition-Based) |
| Trigger | Equipment failure | Fixed time or usage interval | Real-time condition data + AI |
| Downtime Type | Unplanned, often lengthy | Planned, but sometimes unnecessary | Planned, precisely timed |
| Parts & Labor Cost | High (emergency rates, expediting) | Moderate (routine, but over-servicing) | Optimized — work done only when needed |
| Asset Life Utilization | Fully consumed, but catastrophically | Partial life consumed prematurely | Optimized — near-full useful life extracted |
| Data Dependency | None | Basic (MTBF estimates) | High (sensors, AI models, historical data) |
| Best Applied To | Non-critical, low-cost, easily replaced assets | Regulatory-mandated or safety-critical systems | High-value, high-impact production assets |
The honest answer is that no single strategy is universally superior. Reactive maintenance is perfectly rational for a low-cost conveyor gearbox where replacement takes 20 minutes. Preventive maintenance remains appropriate where regulatory compliance or safety demands fixed inspection intervals. Predictive maintenance delivers its highest value on assets that are expensive to repair, central to production flow, and where failure signatures are detectable in advance — which describes the majority of critical equipment in a modern factory.
In an AI-driven factory, these strategies are not chosen once and fixed. The maintenance strategy for each asset can be continuously re-evaluated based on criticality, failure history, and sensor data availability.
How Predictive Maintenance Works in a Real Factory Environment
Data Collection: Sensors, PLCs, and Machine Signals
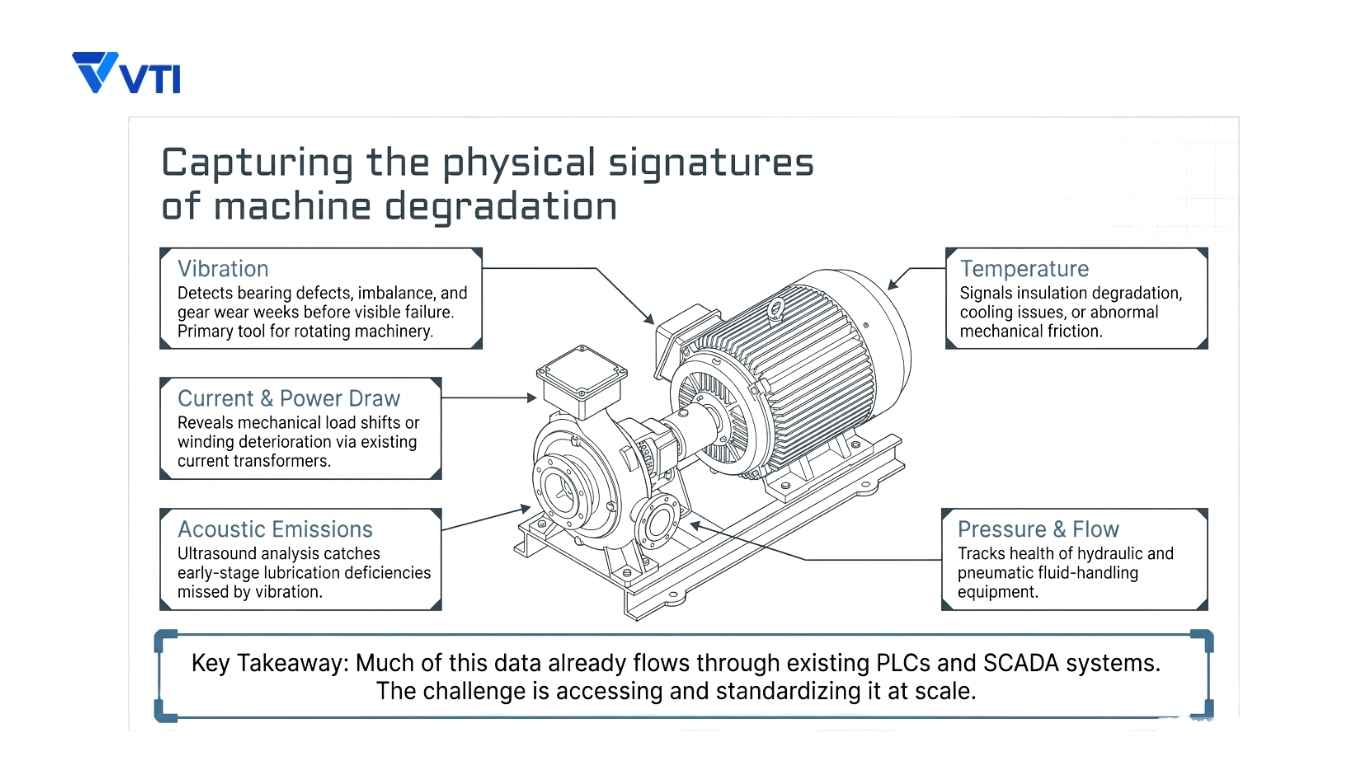
Effective predictive maintenance begins at the data layer. The most commonly monitored parameters include:
- Vibration: The primary diagnostic tool for rotating machinery. Vibration analysis can detect bearing defects, imbalance, misalignment, looseness, and gear wear — often weeks or months before visible failure.
- Temperature: Critical for motors, drives, and thermal processes. Abnormal rise frequently signals insulation degradation, cooling system issues, or increased mechanical friction.
- Current and Power Draw: Changes in motor current patterns can reveal mechanical load shifts, rotor bar failures, or winding deterioration — without requiring additional hardware beyond a current transformer.
- Pressure and Flow: Essential for hydraulic systems, pneumatics, and fluid-handling equipment.
- Acoustic Emissions: Ultrasound analysis can detect lubrication deficiencies and early-stage bearing damage that vibration sensors alone may miss.
In modern facilities, much of this data already flows through existing PLC infrastructure and SCADA systems. The challenge is rarely in generating the data — it is in accessing, standardizing, and making sense of it at scale. A mature AI-driven factory treats this data as a strategic asset, not simply as operational telemetry.
Data Processing: Edge vs. Cloud in an AI Factory Architecture
Data processing architecture is one of the most consequential and least-discussed aspects of predictive maintenance implementation. The two primary approaches — edge computing and cloud processing — are not competing alternatives. In an AI-driven factory, they are complementary layers of the same architecture.
- Edge computing places processing power at or near the machine. Low-latency anomaly detection — the kind that can trigger an immediate alert or automatic equipment shutdown before a failure propagates — must happen at the edge. Sending raw vibration data to a cloud server and waiting for a response introduces unacceptable latency for time-critical applications. Modern edge devices can run lightweight AI inference models locally, flagging anomalies in milliseconds.
- Cloud processing handles the heavier analytical workloads: training and retraining machine learning models, running fleet-level diagnostics across multiple plants, maintaining historical data archives for long-term trend analysis, and enabling cross-site benchmarking. Cloud infrastructure is also where predictive maintenance data connects with enterprise systems — feeding into production planning, inventory management, and strategic decision-making.
The emerging standard in industrial AI is an edge-first architecture for operational alerts, feeding into cloud systems for strategic analytics — creating a data loop that gets smarter with every maintenance event.
AI and Analytics Models for Failure Prediction
The analytical core of a modern predictive maintenance system can take several forms, each with different data requirements and organizational maturity implications:
- Anomaly Detection Models establish a “normal” behavioral baseline for each asset and flag deviations. They require no historical failure data to train — a significant advantage when deploying on assets with no prior monitoring history. Isolation Forest, Autoencoder networks, and One-Class SVM are common approaches.
- Supervised Classification Models are trained on labeled datasets containing known failure signatures and normal operating data. They deliver higher precision predictions but require a sufficient history of documented failures to be effective. Gradient boosting models (XGBoost, LightGBM) and deep learning architectures like LSTM networks are widely used here.
- Physics-Based Models incorporate domain knowledge about how specific failure mechanisms develop — for example, the Hertzian contact stress model for bearing wear. These models can be highly accurate for well-understood failure modes, even with limited historical data.
In practice, the most effective AI-driven predictive maintenance systems combine multiple approaches: an anomaly detection layer provides broad coverage across all monitored assets, while supervised models deliver high-confidence, failure-specific predictions on assets with sufficient operational history.
Alerts, Workflows, and Maintenance Actions
A predictive alert is only as valuable as the action it enables. In a well-designed system, the workflow looks like this: an anomaly is detected at the edge layer → a work order is automatically generated in the CMMS → maintenance priority and scheduling are proposed based on failure probability and production schedule → a technician is dispatched with the right spare parts and diagnostic context already in hand.
The Role of MES, ERP, and CMMS in the PdM Ecosystem
Predictive maintenance does not operate in isolation. In an AI-driven factory, it is one node in a larger data ecosystem:
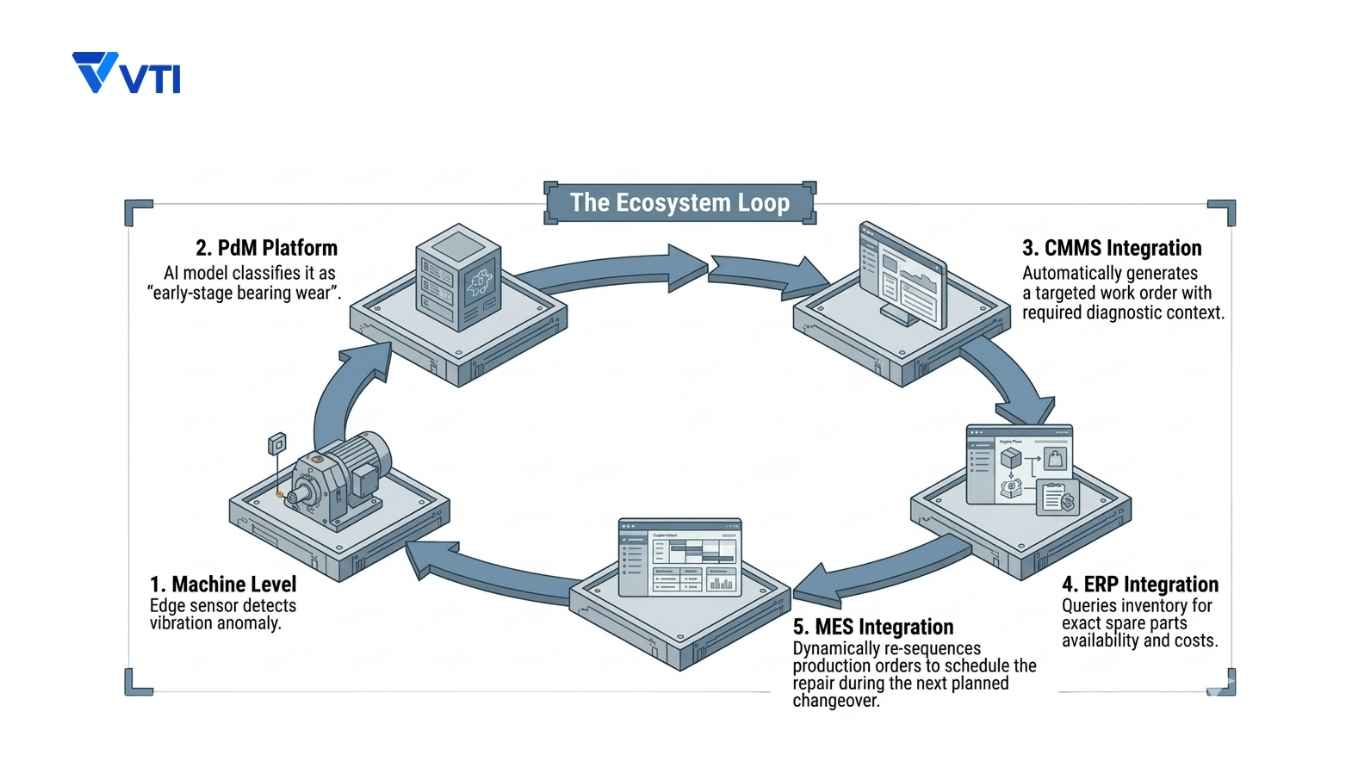
Machine → IoT Gateway → PdM Platform → CMMS → MES → ERP
- The CMMS (Computerized Maintenance Management System) receives work orders triggered by PdM alerts and tracks their execution, parts consumption, and resolution.
- The MES (Manufacturing Execution System) receives machine health status from the PdM platform and can dynamically re-sequence production orders around planned maintenance windows.
- The ERP receives maintenance cost data and spare parts consumption, enabling procurement planning and cost analysis at the enterprise level.
This integration is what separates factories that use predictive maintenance as a standalone tool from those that use it as an active component of their operational intelligence architecture. The data flows both ways — production context from MES can inform how PdM models interpret equipment behavior under different load conditions.
Business Impact: ROI and Performance Improvements
While results vary by industry, asset type, and implementation maturity, published benchmarks and industry case studies consistently point to meaningful improvements across several dimensions:
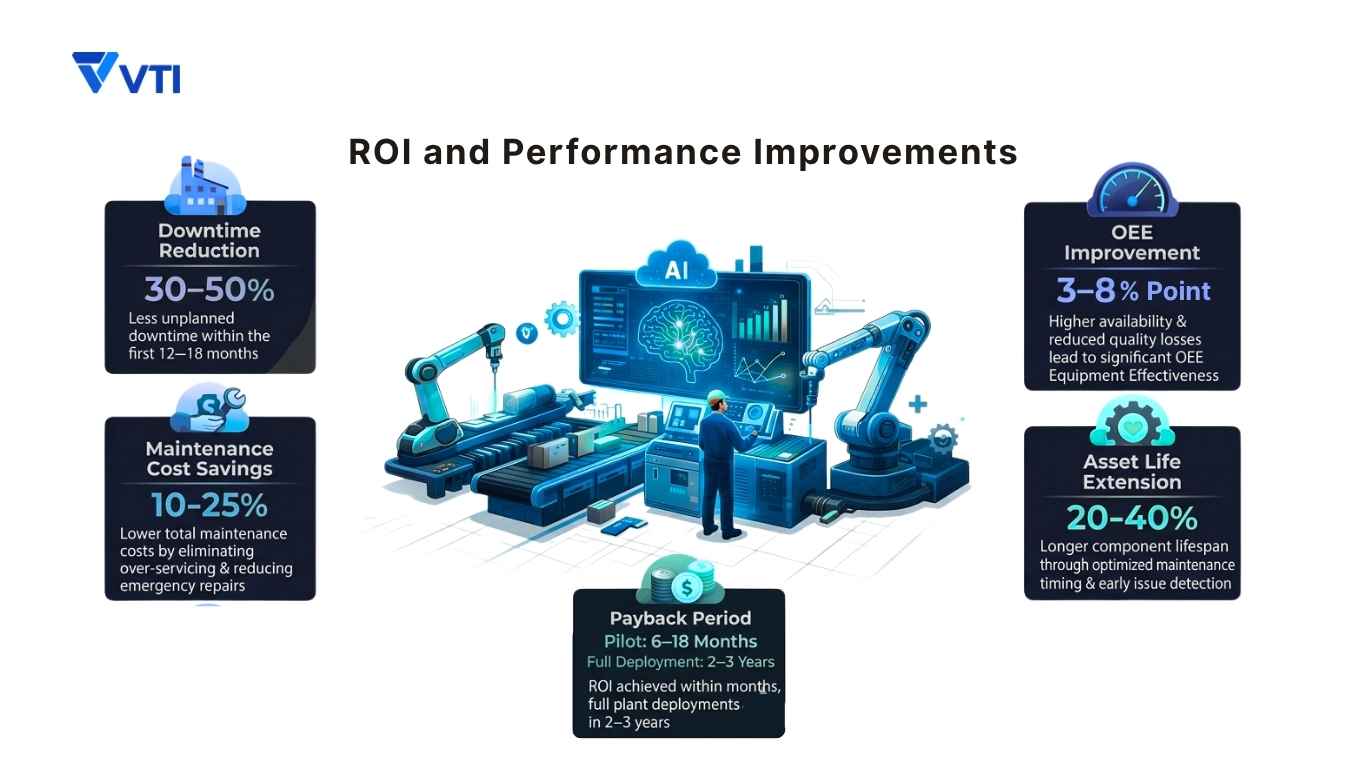
- Downtime reduction: Well-implemented PdM programs typically reduce unplanned downtime by 30–50% within the first 12–18 months. (Koerber)
- Maintenance cost savings: Total maintenance costs — including labor, parts, and contracted services — typically decline by 10–25% as over-servicing is eliminated and emergency repair costs fall.
- OEE improvement: The combination of higher availability and reduced quality losses from process disruptions typically contributes 3–8 percentage points of OEE improvement.
- Asset life extension: Optimized maintenance timing, combined with early detection of operating conditions that accelerate wear, can extend major component life by 20–40%.
- Payback period: For a well-scoped pilot project, most manufacturers report payback within 6–18 months. Full plant deployments typically achieve payback within 2–3 years.
Step-by-Step Implementation Roadmap
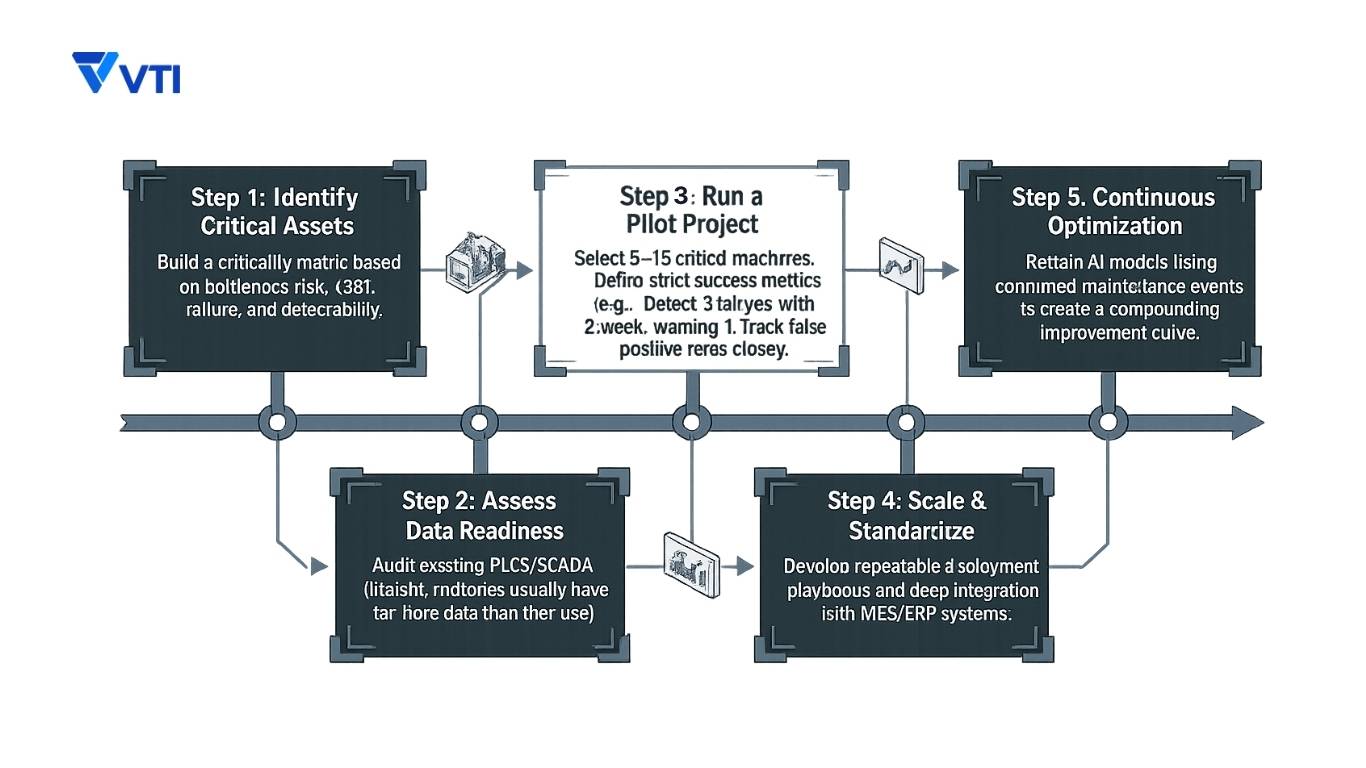
Step 1 – Identify Critical Assets
Begin with an asset criticality assessment. The highest-priority candidates for predictive maintenance share three characteristics: they are bottleneck assets whose failure stops production; they have a high failure cost (expensive repairs, long lead times for parts, or significant secondary damage when they fail); and they have failure modes that are detectable in advance through condition monitoring.
Document both the cost of failure and the detectability of failure for each candidate asset. This creates a prioritization matrix that focuses the program on assets where PdM delivers the highest return.
Step 2 – Assess Data Readiness
Before selecting technology, audit your existing data environment to identify low-effort, high-value sources. Key questions include: what sensors are already accessible? What is the data quality and sampling rate from existing PLCs and SCADA systems?
In the diverse APAC manufacturing landscape, bridging the gap between legacy hardware and AI requires a robust communication strategy:
- Standardize Protocols: Leverage Modbus for cost-effective integration of older assets, while adopting OPC-UA as the “secure gold standard” for modern, structured data flow from OT to IT.
- Solve Data Silos: Use IIoT Gateways to “translate” proprietary OEM data into cloud-friendly formats like MQTT or JSON, unlocking variables already logged in PLCs but never utilized.
- Leverage 5G: In high-density environments (common in hubs like China or Singapore), Private 5G provides the ultra-low latency and wireless capacity needed to connect thousands of sensors without the cost of complex cabling.
A thorough assessment often reveals that the factory already generates the necessary data; the challenge is simply building the “digital plumbing” to pipe it into your analytics platform.
Step 3 – Run a Pilot Project
Select a single production line or a tightly defined group of 5–15 critical machines for the pilot. The pilot serves two purposes: it generates proof-of-value data for the broader business case, and it surfaces the integration and organizational challenges that will need to be solved at scale.
Define success metrics upfront and make them specific. “Reduce downtime” is not a success metric. “Detect at least 3 bearing failures with a minimum 2-week advance warning across the pilot asset group within 6 months” is a success metric. Equally important: track false positive rates. A system generating daily alerts that turn out to be nothing will destroy technician trust faster than any technical failure.
Step 4 – Scale Across Production Lines
Scaling is where many predictive maintenance programs stall. The challenges that were manageable at pilot scale — data integration complexity, model tuning for different asset types, change management with maintenance teams — multiply as the program expands.
Successful scaling requires standardized deployment playbooks: documented sensor installation specs, data pipeline configurations, alert threshold logic, and workflow integrations that can be replicated consistently across lines and plants. Integration with MES and ERP systems at this stage is what transforms PdM from a maintenance tool into a factory-wide operational intelligence capability.
Step 5 – Continuous Optimization
Predictive maintenance is not a set-and-forget system. AI models drift as equipment ages, operating conditions change, and new failure modes emerge. A mature program includes regular model retraining cycles, structured review of confirmed failures and near-misses, and ongoing expansion of monitored parameters as new failure patterns are identified.
The most advanced AI-driven programs use confirmed maintenance events as training data to continuously improve model accuracy — creating a compounding improvement curve where the system gets better the longer it operates.
Common Use Cases in Manufacturing
CNC Machines: Spindle and Vibration Monitoring
The spindle is the heart of a CNC machining center and one of the most expensive components to replace. Vibration analysis on spindle bearings can detect the onset of bearing wear, thermal imbalance, and tool holder runout weeks before they affect part quality or cause catastrophic spindle failure. In high-mix machining environments, integrating spindle health data with the MES allows the system to flag at-risk spindles before they are scheduled for a high-precision operation where a subtle vibration anomaly would result in scrap.
Injection Molding Machines: Temperature and Pressure Anomaly Detection
In injection molding, process consistency is product quality. Predictive maintenance on these machines focuses heavily on mold temperature uniformity, injection pressure profiles, and barrel heating element behavior. Gradual drift in any of these parameters — invisible to manual inspection between cycles — can produce subtle part defects that only become apparent during downstream quality checks. AI-driven monitoring catches these trends early, enabling corrective action before a quality excursion occurs.
Low-Cost Predictive Maintenance on Conveyor Motors
Conveyor and transfer system motors are high-frequency, relatively low-cost assets — but their failure can halt an entire line. Current signature analysis on conveyor drive motors is a cost-effective approach: it requires no additional sensors beyond a current transformer, detects bearing wear and mechanical overload, and can be deployed across hundreds of motors simultaneously. The alert-to-work-order workflow on these assets can be fully automated, with maintenance scheduled during planned breaks without any manual triage required.
Predictive maintenance for interdependent robot failure modes
Industrial robots introduce a unique predictive maintenance challenge: their failure modes are interdependent across joints, drives, encoders, and end-of-arm tooling. AI-driven monitoring of joint torque signatures, motor current profiles, and positioning repeatability can detect early-stage gear wear in robot joints — one of the most expensive repair events in a robotic cell. As manufacturers increase robot density, the ability to predict robot maintenance needs with precision becomes a critical factor in production reliability.
Challenges and How to Overcome Them
Data Quality and Inconsistency
The most common barrier to predictive maintenance success is not technology — it is data. Sensors with inconsistent calibration, PLCs with sampling rates too low to capture high-frequency failure signatures, and operational data that is not time-synchronized to maintenance events all undermine model accuracy. The solution is to treat data infrastructure as a first-class engineering discipline, not an afterthought.
False Positives and Alert Fatigue
A predictive maintenance system that cries wolf loses its audience. Maintenance technicians who learn that alerts frequently do not correspond to real problems will start ignoring them — defeating the entire purpose of the program. Managing false positive rates requires iterative model tuning, contextual filtering (an anomaly during a known production changeover is not a failure signal), and transparent communication with maintenance teams about the current confidence level of different alert types.
Integration with Legacy Equipment
Not every asset in a factory is equipped with digital interfaces. Older machines may have no PLC connectivity, no digital sensors, and no standard communication protocols. In these cases, retrofitted wireless sensor nodes — accelerometers, temperature sensors, and ultrasound probes with edge processing capability — can add predictive monitoring capability without requiring machine modification. The cost per point has dropped dramatically over the past five years, making legacy equipment integration increasingly practical.
Change Management on the Shop Floor
The most underestimated challenge in any predictive maintenance program is human. Maintenance supervisors often see AI recommendations as a threat to their authority. Meanwhile, production managers used to reactive work may ignore predictive alerts. They act only when problems feel urgent.
The solution is as much cultural as it is technical. Involve maintenance teams in model development and alert threshold calibration. At the same time, celebrate early wins visibly to build trust. Most importantly, frame predictive maintenance as a tool that makes skilled technicians more effective. It should never replace their judgment.
Practical Solutions
Start small: A pilot-first approach allows the organization to build proof points, develop internal expertise, and identify integration challenges at manageable scale before committing to full deployment.
Combine domain expertise with data models: The best predictive maintenance models are built with input from both data scientists and experienced maintenance engineers. Domain knowledge about how specific failures develop is irreplaceable — it informs feature engineering, failure labeling, and threshold calibration in ways that pure data-driven approaches cannot replicate.
Build cross-functional teams: Sustainable predictive maintenance programs require collaboration between maintenance, operations, IT, and data engineering. Organizations that treat PdM as solely an IT project or solely a maintenance project consistently underperform those that build integrated teams with shared accountability.
Scaling Predictive Maintenance Across Multiple Facilities
For multi-plant manufacturers, scaling predictive maintenance from a single facility to a global network introduces a distinct set of challenges that go beyond technology — they are fundamentally organizational and governance challenges.
How HQ Standardizes PdM Across Global Plants
The most effective approach is a federated model: a global framework defined at the corporate level, with controlled flexibility for local adaptation. The framework defines mandatory standards — sensor specifications, data formats, communication protocols, alert classification logic, and KPI definitions — while allowing individual plants to adapt implementation details to local equipment configurations, regulatory requirements, and operational contexts.
A global predictive maintenance platform provides HQ engineering teams with visibility into asset health across the entire network, enabling cross-plant benchmarking, centralized model development, and rapid propagation of failure pattern knowledge from one facility to others.
Balancing Global Standards with Local Flexibility
The tension between standardization and local flexibility is real and permanent. Imposing a one-size-fits-all model configuration without local validation will produce poor alert quality and rapid loss of confidence.
The resolution is to standardize the process — how models are validated, how thresholds are set, how alerts are classified — while allowing the parameters to be tuned locally. This preserves the consistent benefits of standardization while respecting the genuine diversity of manufacturing environments across a global network.
Data Governance Across Regions
As predictive maintenance programs scale globally, data governance becomes a strategic issue. Questions of data sovereignty (where machine health data can be stored and processed), cross-border data transfer compliance, and standardized data taxonomies for cross-plant comparison all require explicit policy decisions at the corporate level.
Manufacturing organizations that invest in a robust data governance framework early — defining data ownership, access controls, retention policies, and quality standards — find that scaling becomes dramatically easier. Those that defer these decisions find that each new plant deployment requires re-solving the same governance problems from scratch.
How to Choose the Right Predictive Maintenance Solution
Key Evaluation Criteria
When selecting a predictive maintenance platform, focus on these practical criteria:
- Model accuracy on your specific asset types: Ask vendors for validation data on equipment similar to yours. Avoid relying only on general benchmark statistics.
- Integration depth with your existing ecosystem: The platform must write work orders directly into your CMMS. It should also share health data smoothly with your MES. Otherwise, manual processes will create extra workload and reduce long-term value.
- Time-to-value: How quickly can you see meaningful results after signing the contract? Platforms that need 12+ months of data before delivering predictions are hard to justify.
- Explainability: In a manufacturing environment, black-box models are difficult to trust. Maintenance engineers need clear explanations of why a machine is likely to fail. This helps them make confident decisions.
- Scalability: Can the platform handle the full data volume, asset count, and site complexity of your entire operation — not just the pilot phase?
Future Trends in Predictive Maintenance
AI Model Advancements
The next generation of predictive maintenance AI is moving beyond pattern recognition toward causal reasoning. Foundation models trained on broad industrial datasets are beginning to enable zero-shot or few-shot prediction on asset types with no historical failure data. Multimodal models that combine vibration, thermal imaging, acoustic, and process data into unified failure predictions are also maturing rapidly.
Edge Computing Adoption
The cost and capability of edge computing hardware has improved dramatically. Modern industrial edge devices can run complex inference workloads locally, enabling sub-millisecond anomaly detection without cloud connectivity. As edge hardware becomes more capable and cost-effective, the operational case for full edge deployment becomes increasingly compelling.
Integration with Smart Factory Ecosystems
Predictive maintenance is becoming one input into a broader autonomous factory operating model. In the most advanced AI-driven factories, machine health data flows directly into digital twin platforms.
These platforms simulate failure scenarios before they happen. Production planning systems then re-optimize schedules around predicted maintenance needs.
Therefore, quality systems also correlate equipment health trends with product quality outcomes. The boundary between maintenance intelligence and production intelligence is dissolving.
The Move Toward Prescriptive Maintenance
The next evolution beyond predictive maintenance is prescriptive maintenance. These systems not only predict failures, but also recommend specific corrective actions. In addition, they optimize maintenance resource allocation and orchestrate the procurement, scheduling, and execution of maintenance work automatically.
Early prescriptive maintenance systems are already being deployed by leading manufacturers. As AI capabilities continue to mature, the gap between prediction and prescription is closing rapidly.
Conclusion: Turning Maintenance into a Strategic Advantage
The manufacturers who are winning on operational efficiency are those who have fundamentally reframed how they think about maintenance. It is a capability that, when executed well, directly determines production output, product quality, and customer delivery performance.
Predictive maintenance — particularly when integrated into a broader AI-driven factory architecture — is the mechanism by which that reframing becomes operational. It converts maintenance from a reactive function that absorbs cost into a proactive system that generates value.
FAQs
What is predictive maintenance in manufacturing? Predictive maintenance is a strategy that uses real-time sensor data and AI analytics to detect equipment degradation before it causes failure.
How does predictive maintenance reduce downtime? By detecting failure signatures weeks or months before a breakdown occurs, predictive maintenance converts unplanned emergency stoppages into planned maintenance windows that can be scheduled to minimize production impact. In AI-driven factory environments, the system can also automatically re-sequence production orders around upcoming maintenance events.
What data is required for predictive maintenance? The most commonly used data types are vibration, temperature, electrical current, pressure, and acoustic emissions from production equipment. Much of this data is already accessible via existing PLC infrastructure and SCADA systems. Historical maintenance records and failure logs are also valuable for training supervised prediction models.
What is the difference between predictive and preventive maintenance? Preventive maintenance follows a fixed schedule — service every 3 months, regardless of actual equipment condition.
Is predictive maintenance suitable for small or mid-sized factories? Yes, with the right scoping. The key is to focus initial investment on a small number of high-criticality, high-cost-of-failure assets where the economics are clear.




