



![[FREE EBOOK] Strategic Vietnam IT Outsourcing: Optimizing Cost and Workforce Efficiency](https://vti.com.vn/wp-content/uploads/2026/06/ebook-it-outsourcing.png)
Despite billions in global investment, research showed that over 95% of AI pilots fail to deliver measurable business impact. Every boardroom conversation about AI eventually hits the same wall. The strategy is sound. The use cases are clear. The investment has been approved. And yet the pilots that looked promising in a controlled environment refuse to scale when they meet real operations. But in most cases, it is not the AI model. One of the real constraints, almost always invisible at the point of decision, is the absence of an AI-ready data foundation.
Your current AI is running on a base that was never built for AI. It was built for reports, dashboards, and human analysts who could fill in the gaps themselves.
To help you increase the chance of scaling AI systems beyond pilots, this article explains:
- What an AI-ready data foundation actually is,
- Why most enterprise data does not qualify,
- What the blueprint for building one looks like – across three interdependent layers that every organization needs before AI can scale beyond a pilot.
What Is an AI-Ready Data Foundation?
An AI-ready data foundation is not simply clean data. It is data that is structured, documented, governed, and delivered in a way that machines – not just humans – can consume, interpret, and act on reliably. That distinction matters more than most business leaders realize.
Most organizations optimize their data for reporting and human decision-making. Meanwhile, AI requires something different:
“Data that travels through automated pipelines without breaking, carries context about what it means and where it came from, and arrives at AI systems in the right format at the right time.”
That is a fundamentally different standard – and most enterprise data does not meet it.
AI-ready data has five core attributes:
- Consistent: The same concept means the same thing across all systems – a “customer” in the CRM is the same entity as a “customer” in the billing platform.
- Documented: Every dataset carries context – what it represents, where it came from, and how it was collected.
- Governed: Clear ownership, access rules, and accountability exist at the data source, not just at the reporting layer.
- Connected: Data from different systems can be joined without losing integrity or introducing conflicting definitions.
- Deliverable: Data can move through automated pipelines to AI systems reliably and at scale, without manual intervention.
In the past, a report tolerated gaps and inconsistencies because a human analyst could fill them in manually. But an AI model cannot do that (or maybe not yet), but treats every gap as information – and scales whatever is in the data, including the errors.
Why Does Building an AI-ready Data Foundation Matter Now?
The Scale of the Problem
Over 80% of enterprise data is unstructured – trapped inside PDFs, emails, call recordings, and images. However, historically, fewer than 1% of it has been formatted for deep analytical use, and less than 1% of this data is in a format suitable for direct AI consumption without massive preprocessing today. Most organizations face a widening gap because they have far more raw data (that is bloating every day) than they have AI-ready data.
Most Stuck At A Proof of Concept
PoC environments run on clean, curated samples while practical environments run on everything. A model that performs at 94% accuracy on a curated sample can degrade significantly when it encounters the inconsistencies, gaps, and format variations of live enterprise data. The moment AI touches real enterprise data at scale, unprepared foundations break.
Employees Do Not Trust AI Outputs
When AI produces a recommendation, but no one can trace it back to a proven source, trust collapses. AI-ready data includes lineage and provenance – so when an AI system makes a call, the reasoning is auditable. Governance is not just a compliance requirement, but the foundation of adoption.
The Compounding Cost of Waiting
Every month, an organization runs AI on an unprepared foundation, accumulating technical debt in three directions:
- Wasted compute on dirty data,
- Failed deployments that damage internal confidence, and
- Decisions made based on outputs no one can fully trust.
Waiting to build this foundation creates an exponential debt loop. Unstructured data pools are expanding at a compounding rate of 55% to 65% annually. The longer an organization delays implementing an AI-ready data pipeline to process the data, the more chaotic, disconnected, and complex its data structure becomes. Eventually, making future integration significantly more difficult and expensive.
Common Challenges to Prepare Data Readiness for AI
Most organizations that struggle to scale AI are not held back by a lack of ambition or budget, but by the following recurring obstacles:
Poor data quality
Poor data quality – inconsistent formats, unstructured data, outdated records, undocumented fields, and systems that were never designed to integrate – compounds the problem at every layer.
Even the most capable AI model cannot produce reliable outputs when the data feeding it is contradictory or incomplete. The consequence is not just a technical failure. It is financial exposure from failed deployments, reputational risk from biased decisions, and eroded confidence in AI’s value across the organization.
Data Silos and Ownership Gaps
Departments protect their data, while AI requires cross-functional data sharing. When data cannot move freely across the organization, preparation takes longer, inconsistencies multiply, and the AI systems that depend on such data inherit every gap that ownership disputes left behind. No amount of pipeline investment fixes a problem that starts with people not agreeing on who controls what.
In other words, before a technical challenge, data silos are a governance & leadership challenge. Without executive-level decisions about access and accountability, architecture investments solve the wrong problem.
Governance for Reports, Not Pipelines
Traditional data governance was designed for static datasets reviewed by human analysts. AI requires governance that applies rules while data is moving – what practitioners call governance-in-motion.
There is also a security dimension that static governance frameworks rarely anticipate: generative AI introduces new exposure points, including data leakage through model outputs and prompt injection attacks that manipulate what an AI system retrieves.
The Skills and People Gap
Technology is only half the equation. Organizations that invest in data infrastructure without investing in the people who work with it discover a different kind of bottleneck. Data teams stretched across complex, siloed environments cannot simultaneously manage existing systems and deliver AI-ready data for new initiatives.
Beyond technical staff, broader data literacy matters – employees who cannot interpret or question AI outputs undermine adoption regardless of how well the foundation is built. The AI Governance and Evaluation guide covers how to build the human accountability layer alongside the technical one.
3 Layers to Construct a Solid AI-ready data foundation
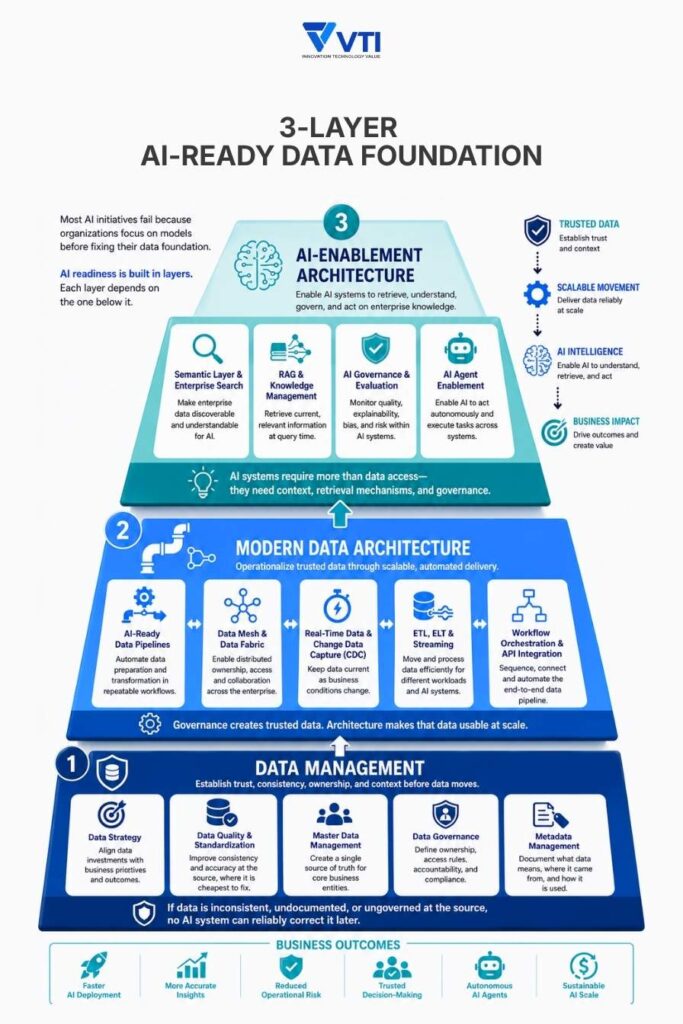
Layer 1: Data Management
This layer establishes the rules, standards, and ownership structures that make your data trustworthy before it moves anywhere.
It comes first for a simple reason: if data is inconsistent, ungoverned, or undocumented at the source, no pipeline or AI model downstream can compensate. Every layer above inherits whatever problems exist here – and has no way to correct them.
- Data Strategy – aligning data investments to business objectives, not just IT roadmaps.
- Data Standardization and Data Quality Management – preparing data for AI, ensuring consistency and accuracy at the source, where it is cheapest to fix.
- Master Data Management – a single source of truth for core business entities: customers, products, suppliers.
- Data Governance – ownership, access rules, accountability, and compliance across the enterprise.
- Metadata Management – documenting what data means and where it came from, so AI systems can interpret it correctly.
Layer 2: Modern Data Architecture
Governance without movement is a filing cabinet. This layer is the operational engine that takes what Layer 1 establishes and delivers it to AI systems – reliably, at scale, and without manual handling. If Layer 1 defines what your data means, this layer ensures it actually gets where it needs to go, in the right shape, at the right time.
- AI-Ready Data Pipelines – automating data preparation inside repeatable, scalable workflows.
- Data Mesh and Data Fabric – organizing data ownership and access across large, distributed enterprises.
- Real-Time Data and Change Data Capture – keeping data current as business conditions change, not just at the next scheduled batch run.
- ETL, ELT, and Streaming – the movement patterns that feed different types of AI systems.
- Workflow Orchestration and API Integration – sequencing and connecting the full pipeline end-to-end.
Layer 3: AI-Enablement Architecture
This layer is where data becomes intelligence. Even perfectly governed and delivered data is unusable if AI systems cannot retrieve or interpret it. This layer connects prepared data to AI systems and ensures they can find what they need, understand what it means, and act on it reliably. It is also where governance extends into the AI systems themselves – accountability does not stop at the pipeline.
- Semantic Layers and Enterprise Search – making data findable and interpretable for AI, not just for human analysts.
- Retrieval-Augmented Generation (RAG) and Knowledge Management – enabling AI to retrieve relevant, current information at query time rather than relying solely on training data.
- AI Governance and AI Evaluation Frameworks – accountability, explainability, and bias monitoring within AI systems themselves.
- AI Agents Enablement – the infrastructure that allows AI to act autonomously, not just generate answers.
AI Data Preparation Across Industries: Key Nuances to Know
Every industry runs on data, but not the same data – and not with the same gaps. The systems, formats, and ownership structures that shape your data foundation vary significantly depending on your sector.
The snapshots below illustrate how the same three-layer blueprint applies differently in practice. The goal is the same in each case: help you recognize where your industry-specific challenges sit within the broader framework before you start building.
Retail
Demand forecasting, personalized recommendations, and inventory optimization are the AI outcomes most retailers are chasing. Delivering them requires a data foundation that unifies transaction data, customer behavior signals, and supply chain inputs – across systems (CRM, POS, Inventory,…) that were rarely built to talk to each other.
In Retail, the data volume is rarely the problem. Most retailers have more than enough of it.
What they lack is consistency. Product categories differ between systems. Customer identifiers do not match across touchpoints. Historical sales data carries undocumented anomalies from promotions or stockouts that no one recorded at the time.
For most retailers, the highest-priority first step is master data management – establishing a single, consistent definition of product and customer entities before attempting to connect any downstream Retail AI system.
Manufacturing
Predictive maintenance, quality defect detection, and supply chain optimization sit at the top of most manufacturers’ AI agendas. Realizing them requires a data foundation that connects sensor data, production logs, and fault history in real time. The infrastructure for collection is often already there – IoT sensors and SCADA systems generate significant volumes of operational data across most production environments.
The gap is in the labeled fault history. Past equipment failures are recorded inconsistently, buried in free-text fields, across systems that were never designed for machine learning. An AI model cannot learn from records it cannot interpret.
The highest-priority first step is a structured labeling initiative – converting historical maintenance records into a format that AI models can actually learn from.
Where to Start: Three Decisions for Business Leaders
The organizations that scale AI successfully are rarely the ones that moved fastest. They are the ones who resisted the pressure to deploy before the foundation was ready. Understanding the blueprint in this article is a start. Acting on it requires three leadership decisions – not technical tasks, but choices that only the executive team can make.
Decision 1: Assess Before You Build
Before committing to any technology investment, audit what data you actually have: who owns it, how consistent it is, whether it is documented, and whether it meets even the basic preconditions of an AI-ready data foundation. Most organizations discover they have significantly more data debt than they expected. That discovery is far less costly before a deployment fails than after.
Decision 2: Treat Data Readiness as a Business Program, Not an IT Project
The 3 layers in this blueprint require decisions about ownership, standards, and cross-functional accountability that cannot be delegated to a technical team.
Data governance requires a sponsor with authority over business units. Data standardization requires agreement between departments that may have conflicting definitions.
These are organizational decisions. Executive sponsorship is not optional – it is the precondition for technical progress.
Decision 3: Build in Layer Order
Data Management first.
Modern Data Architecture second.
AI-Enablement Architecture third.
Organizations that try to build Layer 3 without Layer 1 in place consistently spend more, move more slowly, and produce less reliable AI. The sequence is not arbitrary – each layer depends on the integrity of the one beneath it. Skipping ahead does not accelerate delivery; it guarantees rework.
Each topic in this blueprint has its own in-depth guide in this series. Explore the areas most relevant to where your organization is today – or speak with our AI & Data experts to work through your specific starting point.




