



![[FREE EBOOK] Strategic Vietnam IT Outsourcing: Optimizing Cost and Workforce Efficiency](https://vti.com.vn/wp-content/uploads/2023/08/cover-mockup_ebook-it-outsourcing-20230331111004-ynxdn-1.png)

For most organizations today, AI ambition is not the problem.
Budgets are increasing, pilot projects are multiplying, and executive teams have aligned on the strategic importance of the technology. Yet for 43% of organizations, data readiness remains the single biggest barrier to making AI deliver on that ambition. Understanding why that gap exists — and what it actually takes to close it — is where most enterprises need to do more honest work.
When Pilots Succeed, but Scale Fails
The pressure to adopt AI is coming from every direction, and most organizations have responded by doing the right things on paper: developing strategies, establishing dedicated teams, and launching proofs of concept across business units. The real challenge, however, emerges not during experimentation but when successful pilots are expected to scale into business-critical systems.
In the POC (proof of concept) project, technical teams can often compensate for data limitations through manual intervention. Data can be cleaned, reconciled, or supplemented as needed, allowing projects to demonstrate promising results. But those workarounds rarely survive the transition to production.
As AI initiatives move toward enterprise-wide deployment, deeper organizational issues begin to surface. The teams building the solution are often operating separately from the business units that own the processes and data the system ultimately depends on. As a result, stakeholders may hold different assumptions about business objectives, data requirements, ownership responsibilities, and long-term maintenance. What appeared to be a technology challenge quickly reveals itself as a data and governance challenge.
At scale, fragmented data pipelines, inconsistent definitions, and unclear ownership become difficult to ignore. Information remains scattered across legacy systems, cloud platforms, and departmental applications, each maintaining its own version of operational reality. For organizations with limited in-house development capacity, there are often too few internal resources available to bridge these gaps. The numbers reflect this broadly: 79% of organizations report that their AI initiatives are hindered by limited access to the data they need, while an estimated 68% of enterprise data remains unused and unanalyzed despite the costs of storing it.
Generative AI raises the stakes even further. With traditional analytics, poor data quality typically leads to inaccurate reports or flawed insights—a serious but often contained problem. Generative AI changes the nature of that risk. Rather than simply reflecting flawed inputs, AI systems generate new content based on them, reproducing and potentially amplifying errors across every output they create.
In that environment, data readiness is no longer just a technical prerequisite for AI. It becomes a business requirement for trust, governance, and sustainable adoption.
The AI Readiness Illusion
When an AI pilot & POC project succeeds, it tends to produce something that looks like proof of organizational readiness. Dashboards come together, metrics are consolidated, reports run cleanly, and leadership sees a coherent picture of the business for perhaps the first time. That visible output — the polished interface, the connected data, the working demonstration — creates a reasonable but misleading conclusion: that the organization’s data foundation is solid enough to build on.
The problem is that reporting maturity and AI readiness are measuring fundamentally different things.
Every system behind those dashboards was designed with a specific purpose: to explain what has already happened. Data warehouses are optimized for historical queries. KPI frameworks are built around periodic review cycles. Reporting pipelines move data from operational systems into analytical layers — but not back out into the decisions and workflows that need to act on it. The infrastructure works as intended, but it is built for hindsight rather than action.
Even when organizations recognize the need for more real-time data, another challenge often remains. A dataset can be accurate, current, and technically clean yet still be insufficient for AI-driven decision-making. Accuracy alone does not tell an AI system what the data means in a business context. “Without the right business domain, AI might provide answers that sound logical but fail to align with operational realities.”

Consider a straightforward retail scenario: a customer searches for “warm winter coat” in February. A generic AI looks at the search term, notes the customer bought a heavy parka last year, checks that temperatures are still low, and confidently surfaces full-priced, heavy-duty winter coats. The customer leaves without buying anything. The AI was not wrong about the data — it was wrong about the situation. A retail-context-aware system would understand that February sits at the end of the winter selling cycle, that shoppers searching for coats at this point in the season are typically looking for clearance deals or transitional layers rather than a full investment purchase, and that the retailer’s actual priority is clearing winter inventory to make room for spring.
With that context, the recommendation shifts entirely: discounted coats move to the front, transitional pieces are bundled in, and if the customer’s browsing history suggests travel intent, ski-specific options surface instead of casual outerwear. The customer buys two items. The retailer reduces dead stock and increases average order value. The data was the same in both scenarios. What changed was the business context the AI was given to reason with.
Generative AI operates on a different set of requirements entirely. It does not summarize the past — it generates responses, recommendations, and content in real time, drawing on data as it currently exists across the organization’s systems. When that data is governed for reporting rather than for action, the gap between what leadership believes the organization can support and what the infrastructure can actually deliver becomes the central obstacle.
This is the AI readiness illusion — and it is the reason so many organizations arrive at the production stage of an AI initiative with far more confidence than the underlying data infrastructure can justify.
What It Actually Takes to Build on
The organizations that successfully move AI from pilot to production tend to share one common discipline: they assess what they actually have before deciding what to build. That starting point — an honest audit of the current data environment — is less glamorous than deploying a model, but it is what determines whether the model survives contact with production reality.
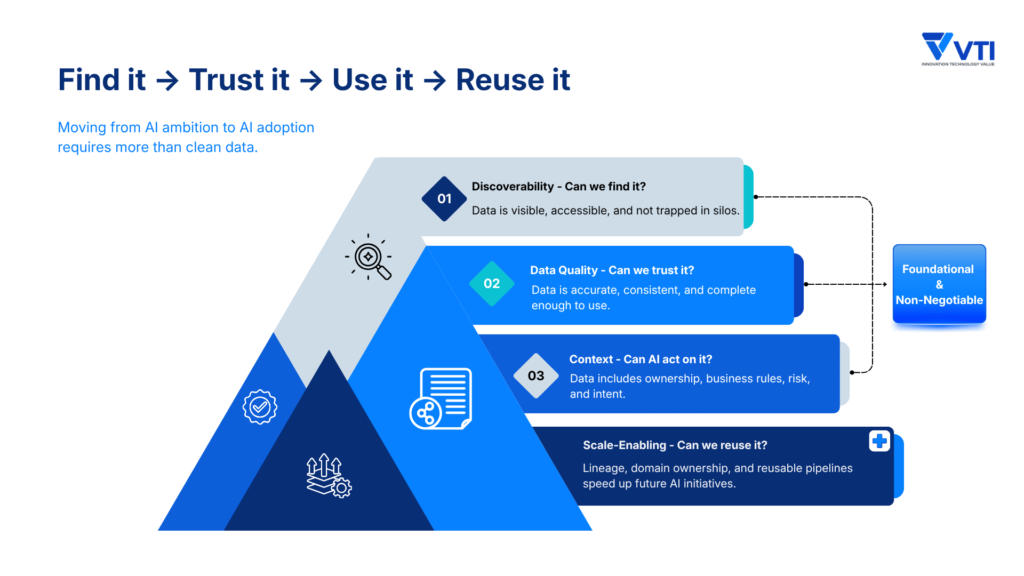
In practice, that assessment tends to surface three areas of foundational and non-negotiable work.
The first is discoverability. Data needs to be visible and accessible across environments, including assets that sit outside formal IT governance — the systems and spreadsheets nobody officially counts, but everyone quietly relies on.
The second is basic data quality: accuracy, consistency, and completeness, evaluated at a level sufficient to be trusted as an input at all.
The third, and the one most often underestimated, is context. A dataset can pass every quality check and still be unusable for AI if it doesn’t carry the business logic around it. “A dataset might be technically accurate, but it’s still insufficient if it doesn’t convey the business implications — who owns the data, what rules are being applied, the level of risk involved in the decision, and what actions are permissible.” This is also where governance becomes concrete: not just who can access data, but what automated systems are authorized to do with it on behalf of users, and within what boundaries.
Beyond these three essentials, a separate set of capabilities — lineage tracking, domain ownership, reusable data pipelines — matters significantly for scale, but isn’t required before the first use case moves forward. These are the investments that compound over time, making each subsequent initiative faster and less costly to build. Organizations that treat them as prerequisites often find themselves waiting indefinitely. Those that build toward them incrementally, use case by use case, are the ones that eventually close the gap.
The practical implication is that data readiness is not a project with a completion date. It is an ongoing capability that matures alongside the organization’s AI ambitions — and the earlier that discipline is established, the more it accelerates everything that follows.
The Return on Getting This Right
There is a realization that tends to arrive late for most organizations: the time spent building a proper data foundation does not delay AI adoption — it determines how far that adoption can actually go.
The first AI use case built on a properly governed data foundation is the hardest because it requires building the infrastructure that did not previously exist. The second use case moves faster because governance frameworks, integration patterns, and data quality standards carry forward. The third is faster still.
Each project adds to a growing set of reusable components and institutional knowledge that reduces the cost and timeline of every subsequent initiative. This compounding dynamic — the flywheel effect that separates organizations scaling AI from those perpetually running pilots — does not emerge from better models or larger budgets. It emerges from the quality and accessibility of the data underneath.
The organizations best positioned to lead on AI over the next several years are not necessarily those with the most advanced technology today. They are the ones currently doing the less visible work of building data foundations that will hold at scale — treating data readiness not as a prerequisite to be checked off, but as a strategic capability to be developed and sustained.




