



![[FREE EBOOK] Strategic Vietnam IT Outsourcing: Optimizing Cost and Workforce Efficiency](https://vti.com.vn/wp-content/uploads/2026/06/ebook-it-outsourcing.png)
Do you know that, in 2025, one in every three businesses reports losing revenue as a direct consequence of poor data quality? Data Quality Management (DQM) has now become the primary determining factor separating high-performing enterprises from those chasing costly algorithmic hallucinations. Especially in this AI era, it is considered the ultimate gatekeeper to success, since AI models amplify bad data rather than fixing it.
Let this guide be the navigator to explore what data quality management really means for enterprise technology leaders in the AI era. By this, you’ll learn:
- Six core dimensions that define quality, plus one critical for the AI-ready data foundation
- The challenges teams face in complex environments,
- Best practices for controlling data in specific industries
Whether you’re starting from scratch or refining an existing program, this roadmap will help you turn data quality from a recurring problem into a competitive advantage.
Why Data Quality Matters Today?
Poor data reliability creates direct business costs across several areas of operation:
- Degrading analytics by feeding dashboards and reports with numbers that do not reflect reality.
- This leads to decision errors when teams base their strategy on seemingly right figures
- Time wasted on reconciling inconsistent records instead of acting on insights.
It doesn’t happen in any single industry, but showing up clearly across different industries:
- In retail, duplicate SKU entries across store and online systems can cause stock counts to disagree, leading to overselling or missed restocking.
- In manufacturing, inconsistent supplier part numbers can delay production when the wrong components are ordered.
As organizations pivot toward the widespread adoption of AI, data quality becomes even more critical.
High-quality data improves the reliability of dashboards and forecasting, helping AI programs avoid stalling before they deliver actual value.
Meanwhile, when the data behind AI tools is inconsistent, employees quickly lose trust in AI’s outputs and fall back on manual judgment. This trust gap often widens during the shift from proof-of-concept to production. A PoC typically runs on a clean, controlled dataset, while real business environments involve fragmented data scattered across regional units and platforms.
In other words, consistently accurate data, not just in technical demos, builds the confidence teams need to rely on AI.
What Is Data Quality Management?
Data quality management is the disciplined set of practices that helps organizations profile, cleanse, validate, govern, and continuously monitor data so it remains fit for later operational and analytical use.
For technology leaders, the strategic value is not just cleaner data but lower execution risk, stronger compliance, and more reliable digital transformation outcomes.
How to Define Quality Data? The Seven Dimensions of Data
Traditionally, we can use six dimensions to define measurable standards for data quality:
- Accuracy: Do the records reflect trusted real-world values? – A record is accurate when it correctly mirrors the real-world event or value it’s meant to represent, free of errors or misrepresentation.
- Completeness: Are the required fields populated? – Completeness comes down to whether a dataset has everything it needs, with no missing values or gaps left unfilled.
- Consistency: Do values align across systems and formats? – When data is consistent, the same record looks and reads the same way, no matter which system or dataset it appears in.
- Timeliness: Is the data refreshed and available when needed? – Timeliness is about freshness, how closely the data reflects the current state of things rather than information that’s gone stale.
- Uniqueness: Are records free of duplicates? – Uniqueness simply means there’s no redundancy; each entity shows up once instead of being duplicated and skewing the numbers.
- Validity: Does the data conform to expected formats or rules? – A value is valid when it follows the rules set for it, whether that’s staying within an accepted range or matching the required format.
Yet, building an AI-ready data foundation calls for the addition of the seventh dimension:
- Contextuality: Does this data account for the real-world situation and business cycle? – AI data quality management must evaluate data within its immediate situational context. Data can be technically perfect yet contextually wrong if it ignores situational things like shifting seasonal behaviors, business priorities (like inventory clearance), or changing user intent.
Let’s take an example to understand this clearly.
Consider a shopper searching an online grocery app for “lemon and honey” at 8:00 PM on a Tuesday in rainy November. A generic AI looks strictly at the data – noting the shopper frequently buys baking ingredients – and surfaces full-sized jars of organic honey and a bag of fresh lemons on the home screen. The user leaves the app.
A context-aware AI, however, recognizes the situation: it’s late evening during flu season, and it’s raining outside. The system deduces the shopper isn’t baking a cake; they are likely nursing a sudden cold or sore throat. By immediately shifting the layout to surface immediate-relief items like cold & flu medication, cough drops, and a single-serving “tea kit,” the app secures the sale and saves the customer a miserable late-night trip to a physical store.
What practices comprise data quality management?
Common, complementary data quality management practices among data stewards and other data professionals include data profiling, data cleansing, data validation, integration, data quality monitoring, data repairing, and metadata management.
| Practice | Definition |
| Data profiling | The process of reviewing the structure and content of existing data to evaluate its quality and establish a baseline against which to measure remediation. |
| Data cleansing | The correction of errors and inconsistencies in raw datasets through standardizing formats, removing outliers, and addressing missing values. |
| Data validation | The verification that data is clean, accurate, and meets specific quality rules, such as range or referential integrity constraints, before it’s considered ready for use. |
| Integration | The process of combining data from different sources and systems into a unified, coherent view so that records can be compared and used consistently. |
| Data quality monitoring | Continuous tracking of datasets to catch schema changes, staleness, or duplication before they compromise data integrity over time. |
| Data repairing | The act of correcting or replacing flawed records once an issue has been identified restores them to a usable, trustworthy state. |
| Metadata management | Techniques that ensure metadata captures data rules, definitions, and lineage, which in turn streamlines broader data quality efforts. |
What are Data Quality Challenges and Their Root Causes?
Common Data Quality Issues
Data quality management is most often undermined by:
- Duplicate record entry: When the same customer is entered more than once under different details
- Retaining outdated information: Lack of revision and ongoing verification when customers change numbers, switch jobs, or update email addresses
- Manual entry mistakes: Misspellings, typos, and selection of wrong options
- Integration conflicts: Different systems push conflicting data into the CRM, leading to data corruption
- Incomplete data capture: Missing key fields during imports of form submissions
These issues are amplified in complex organizations, where data volumes and source complexity across multiple systems and cloud environments make manual inspection impractical.
Root Cause of Data Degradation
These issues rarely happen in isolation — they tend to persist because of deeper, systemic gaps:
- Isolated errors: A single incorrect record can go unnoticed until it impacts an important report or a customer interaction.
- Inconsistent standards: Different teams often follow different data entry rules. When everyone uses their own standards, it’s harder to spot errors.
- “Good enough” checks: If a dataset looks fine with a once-over, teams might assume it’s reliable without deeper checks.
- Volume overload: Large datasets make manual review impractical. If you lack the tools to review them, problems will sneak in.
- Lack of clear ownership: A lack of data ownership results in poor data quality and fragmented practices. Without accountability, users can create “data islands” outside the CRM, undermining system integrity and allowing data issues to go unchecked.
Without clear stewardship, validation rules, and monitoring tools, defects multiply as data moves through pipelines, integration layers, and analytical platforms.
Regional Challenges
These challenges become harder to manage when it comes to multinational enterprises.
Those in Japan, Korea, Singapore, and Malaysia must also address multilingual data handling, cross-border regulatory obligations, and integration with legacy systems not designed for modern governance controls.
The lack of character encoding standardization, fragmented regulatory frameworks across jurisdictions, and technical debt in older systems all compound the issues described above.
Based on our professionals, customer and transaction records must remain accurate across languages, scripts, and jurisdictions while still supporting privacy, access, and reporting requirements — particularly where data reliability directly affects compliance, audit readiness, and cross-border operations.
How Do You Implement a Data Quality Management Program?
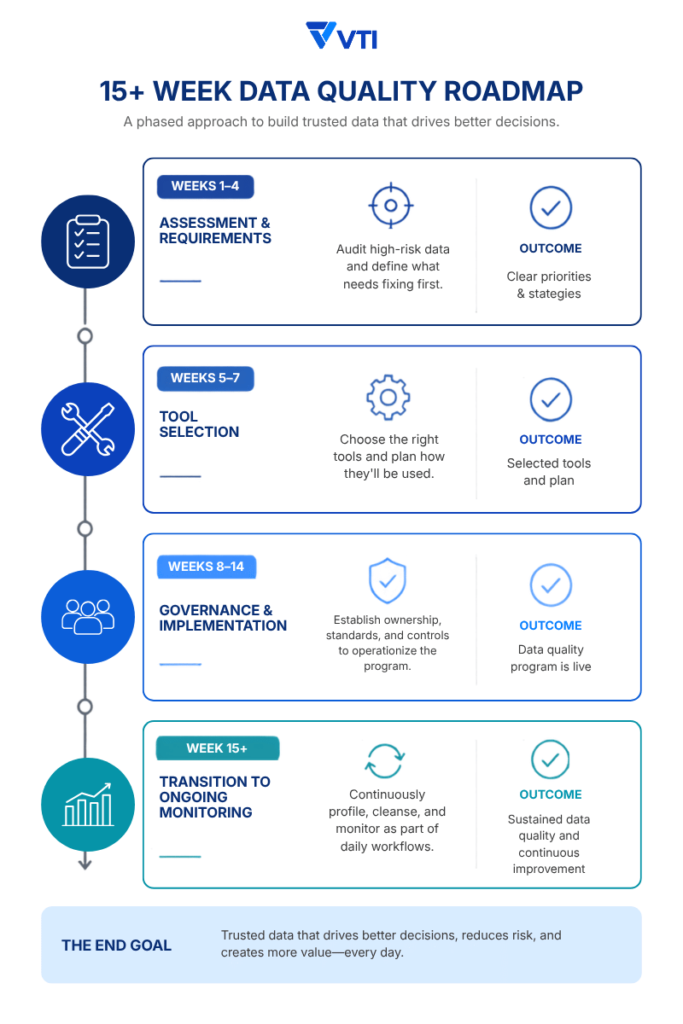
Implementation Roadmap
A successful data quality management program should be implemented in phases that reduce disruption while proving value early.
- Weeks 1–4 – Assessment & Requirements: Start by auditing the highest-risk systems, such as customer, product, or finance data, to scope what needs fixing before anything else.
Also, you shouldn’t just audit what the data is, but when and how it is used. Teams must run “Business Context Mapping” workshops to document special assessment rules like shifting seasonal behaviors, promotional cycles, or situational user intents
- Weeks 5–7 – Tool Selection: Choosing the platforms and capabilities that fit the requirements identified during assessment.
The selected tools must support more than just basic validation rules (e.g., checking if an email has an @ symbol). They need to support semantic layers, knowledge graphs, or real-time business logic engines that allow the AI to cross-reference data with external situational triggers (like weather APIs, seasonal calendars, or live business priorities).
- Weeks 8–14 – Governance & Implementation: Setting up ownership, stewardship, and the controls that put the program into practice.
- Week 15 onward – Transition to ongoing monitoring: Shifting from setup activities to continuous profiling, cleansing, and monitoring built into daily workflows.
Data might remain technically clean, but if the business priority shifts (e.g., moving from a liquidation phase back to full-price spring arrivals), the data rules guiding the AI need to update dynamically. Monitoring must ensure the AI’s situational logic matches the current business reality.
Governance and Ownership
A sustainable operating model requires explicit ownership, clear stewardship, and enforceable accountability across business and technology teams. Best practice is to appoint data owners and stewards for critical domains, document their responsibilities, and define who sets standards, approves exceptions, remediates defects, and signs off on quality thresholds.
For enterprise data quality, this works best as a federated model, where central governance sets policy and metrics while domain teams own day-to-day operations, with role-based controls and automated workflows embedding quality obligations directly into systems.
This governance structure should connect to the organization’s broader data governance, master data management, and compliance programs, so quality controls support a single policy framework rather than operating in isolation.
Master data management initiatives, in particular, should share the same definitions, reference data, and ownership model as DQM to avoid duplicate master records and inconsistent semantics across channels and countries.
Assessment, Quality Assurance, and Monitoring
Effective data quality monitoring combines profiling, anomaly detection, and automated scoring to catch issues before they become business incidents:
- Profiling tools inspect distributions, null rates, format patterns, and cross-field relationships.
- Anomaly detection platforms flag unusual spikes in missing values, schema changes, freshness drift, or duplicate growth.
- Automated systems can convert these checks into a health score, reducing subjective judgment and shifting quality management from periodic audits to continuous control.
This same rigor should be embedded into pipelines through validation rules, referential integrity checks, and conformance testing, confirming that data meets required formats and business logic, that key relationships between master and transactional data stay intact, and that datasets match internal and downstream application standards.
For regulated and audit-sensitive environments, these controls reduce rework and lower the risk of compliance failures.
Success Metrics and Thresholds
Success should be measured through a small set of quantifiable metrics that senior leaders can review regularly, built on the core dimensions of accuracy, completeness, consistency, timeliness, uniqueness, and validity, translated into domain-specific scorecards. However, rather than applying one universal target, baselines and thresholds should be set by business criticality.
For example: A customer master file or regulatory report may demand near-zero tolerance for defects, while exploratory analytics data can accept looser thresholds.
Dashboards, trend analysis, exception logs, and periodic reviews should show whether defects are declining, remediation times are improving, and monitoring coverage is expanding.
To make this improvement visible to CXOs, metrics should connect directly to business outcomes such as fewer failed transactions, lower manual rework, faster close cycles, stronger compliance evidence, and greater confidence in analytics outputs.
Change Management and Adoption
Data reliability improvement usually fails when treated as a tooling project instead of an organizational behavior change.
Executive sponsorship should be paired with cross-functional working groups from business, IT, risk, compliance, and operations, so standards stay realistic and get accepted by the teams that must follow them.
The cultural shift required is moving from “reacting to defects after reports fail” toward “preventing defects at entry, through validation at source, training, and recurring reviews.”
Best practices for data management for your industries
While the core dimensions of data quality apply everywhere, the priorities and risks change, depending on the industry. Here’s how the leading practices play out in different industries:
Retail
Retail data quality centers on keeping product and customer records aligned across every channel a business sells through.
Inventory and SKU data should be synchronized in near real time between physical stores, e-commerce platforms, and warehouses, so stock counts reflect what’s actually available.
Customer profiles also need consistent deduplication across loyalty programs, online accounts, and point-of-sale systems, since the same shopper often gets recorded differently in each.
Beyond accuracy, retailers benefit from validating pricing and promotion data at the point of entry, catching mismatches before they reach customers and damage trust at checkout.
VTI is an end-to-end retail technology partner serving Asia's leading retailers - from supermarkets, convenience stores, to food & beverage brands. With deep expertise across in-store operations, supply chain, and AI-powered retail solutions, VTI helps retailers move faster, scale smarter, and stay ahead of a rapidly shifting market. Explore retail software solutions designed for you today.Ready to transform your retail business with AI & Data?

Manufacturing
In manufacturing, data quality is closely tied to supply chain coordination and production continuity.
Standardizing part numbers and supplier identifiers across procurement, inventory, and production systems prevents the wrong components from being ordered or installed.
Manufacturers also gain from validating sensor and machine data at the source, especially as predictive maintenance and quality control increasingly rely on accurate, timely readings rather than periodic manual checks.
Healthcare
Healthcare data quality carries the highest stakes, since inconsistent or incomplete records can directly affect patient care, not just business outcomes.
Patient records must remain accurate and complete across departments, providers, and systems, so clinicians can work from a single, trustworthy history rather than fragmented records.
Standardized formats matter especially in clinical research and reporting, where inconsistent units, codes, or terminology can make it difficult to compare data or track disease progression.
Given the regulatory weight of healthcare data, validation and audit trails should be built into every stage of capture and storage, supporting both compliance and the accuracy on which patient safety depends.
Final words
Data quality management is no longer optional for organizations that depend on reliable analytics, compliant reporting, and effective AI initiatives. The core message is simple: quality must be built into your data operations from the start, not fixed afterward.
For CXOs and technology leaders, the payoff is lower risk, faster decisions, stronger compliance, and greater confidence in the data that drives your business forward. The question isn’t whether to invest in data quality – it’s how quickly you can turn it into a strategic asset that supports every initiative you launch.
Ready to elevate your enterprise data quality? Connect with our experts to design a tailored DQM strategy that drives business intelligence and AI readiness.




