



![[FREE EBOOK] Strategic Vietnam IT Outsourcing: Optimizing Cost and Workforce Efficiency](https://vti.com.vn/wp-content/uploads/2026/06/ebook-it-outsourcing.png)
According to 2025 IDC data, 63% of enterprise use cases must process data within minutes to be useful – and that window is only getting shorter as AI-driven operations become the business norm.
Real-time data processing has moved from a technical advantage to a baseline expectation for enterprises managing high-velocity environments. The difference between acting on current data and working from hours-old reports can directly affect fraud outcomes, customer retention, and operational throughput.
This guide covers how real-time data processing works, why it matters for enterprise strategy, and how organizations in finance, manufacturing, and retail are applying it — from architecture fundamentals to implementation challenges worth planning for.
What Is Real-Time Data Processing?
Real-time data processing is the continuous ingestion, transformation, and analysis of data within milliseconds to seconds of generation. It allows organizations to act on insights as they arrive, rather than waiting hours or days for batch cycles to complete.
Traditional approaches collect and analyze data at scheduled intervals. Real-time data, by contrast, flows continuously through systems designed for speed and responsiveness — which means your applications can react to events as they occur, whether that’s detecting a fraudulent transaction, adjusting a manufacturing process mid-run, or delivering a personalized recommendation while a customer is still browsing.
Key Benefits of Real-Time Data Processing
Real-time data processing gives organizations the ability to act on information as it arrives, rather than waiting for the next batch cycle to complete. Here’s what that looks like in practice:
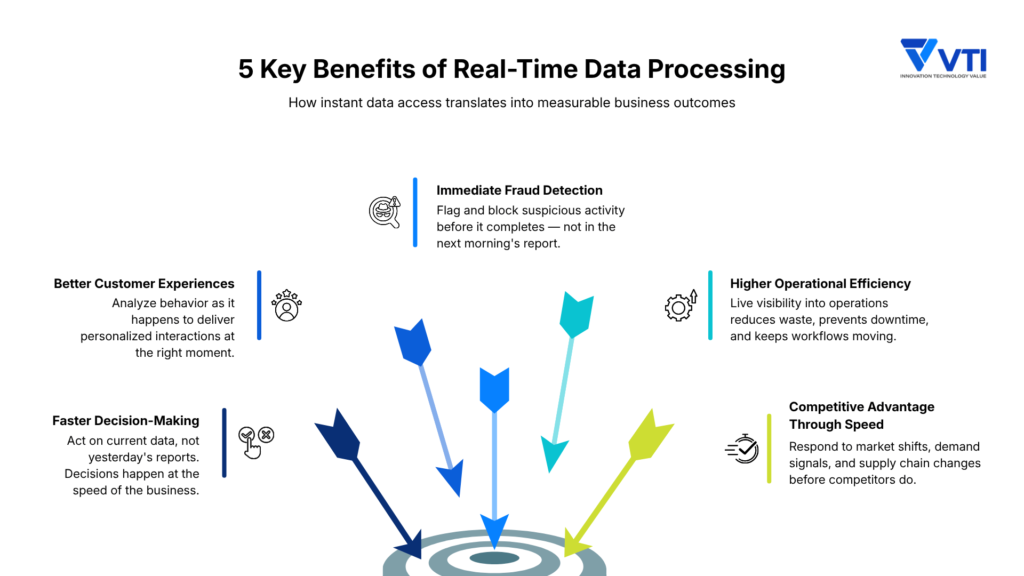
- Faster, better-informed decisions. When data is current, decisions are sharper. A retailer can adjust pricing the moment a competitor runs a promotion. A logistics team can reroute shipments as a disruption unfolds, not hours later.
- Better customer experiences. Real-time data powers personalization at the moment it matters. Recommendation engines, dynamic pricing, and contextual offers all depend on knowing what a customer is doing right now, not what they did last week.
- Immediate fraud and threat detection. Financial institutions processing transactions in real time can flag and block suspicious activity before it completes. The same principle applies to cybersecurity; anomalies get caught as they happen, not in the next morning’s report.
- Higher operational efficiency. In manufacturing, real-time sensor data enables predictive maintenance, catching equipment issues before they cause unplanned downtime. Across industries, live visibility into operations reduces waste and keeps workflows moving.
- Competitive advantage through speed. Companies that act on data faster than their competitors respond to market shifts, inventory changes, and demand signals before others even notice them. In fast-moving sectors, that lag is often the margin.
Real-Time Data Processing Use Cases by Industry
Real-time data processing applies across a wide range of enterprise functions. The use cases below represent the highest-impact applications by sector — each one dependent on data moving through the system fast enough to inform action, not just reporting.
Financial Services
Fraud detection, trading infrastructure, and payment processing all depend on data arriving and being evaluated within milliseconds.
- Fraud detection and anomaly monitoring
- Algorithmic trading and market data analysis
- Instant payment processing and transaction validation
- Risk exposure monitoring
Fraud detection systems using streaming analytics identify suspicious transaction patterns as they occur, allowing financial institutions to block activity before losses materialize — with some implementations reporting up to 60% reduction in fraud losses compared to batch-based methods. Algorithmic trading platforms use real-time data pipelines to monitor market conditions and adjust positions within milliseconds, where latency directly affects returns.
Manufacturing and IoT
Streaming data processing gives operations teams continuous visibility into equipment health, production quality, and supply chain status.
- Predictive maintenance and equipment health monitoring
- Production quality control
- Supply chain disruption response
- Asset tracking and fleet management
Predictive maintenance systems analyze sensor data continuously, identifying failure signals before downtime occurs — reducing unplanned outages by 30–50% in documented implementations. Quality control monitoring flags production defects in real time, allowing operators to adjust parameters before waste accumulates rather than discovering issues during end-of-shift reviews.
Retail and E-Commerce
Real-time data underpins the personalization and inventory systems that directly affect conversion and revenue.
- Dynamic pricing based on demand, inventory, and competitor signals
- Personalized product recommendations
- Real-time inventory tracking and automated reordering
- Clickstream and behavioral analytics
Recommendation engines that process customer behavior as it happens drive 15–20% revenue increases in leading retail implementations. Dynamic pricing systems respond to demand shifts and competitor actions within the same session — an advantage that batch-updated pricing cannot replicate.
AI-Driven Applications
As AI becomes embedded in enterprise operations, real-time data pipelines become part of the model infrastructure itself.
- Real-time feature generation for ML models
- Event-driven model inference
- Retrieval-augmented generation (RAG) pipelines
- Continuous feedback loops for model improvement
This is also where real-time processing intersects directly with AI readiness – models trained on stale features produce stale predictions. Keeping feature pipelines current is increasingly a prerequisite for production AI systems that need to respond to conditions as they change.
Real-Time vs. Batch vs. Manual Processing: How to Choose the Right Approach
Not every workload requires real-time infrastructure. Understanding where each processing model fits, and where it doesn’t, is as important as understanding how real-time systems work.
Batch Processing: Scheduled Efficiency
Batch processing collects data over a defined period and processes it at scheduled intervals. It’s well-suited to workloads where timing isn’t critical — monthly reporting, payroll, historical trend analysis, and large-scale model training.
The approach consolidates data from multiple sources before processing, which supports data quality and reduces infrastructure costs. For organizations analyzing retail sales patterns or running comput-intensive jobs overnight, batch processing remains the more practical and cost-effective choice.
Real-Time Data Processing: Continuous Insights
Real-time data processing runs continuously, delivering low-latency outputs through an event-driven architecture. It’s the right model when a delay in processing directly translates to a worse outcome — fraud that goes undetected, a customer who doesn’t receive a relevant offer, or an equipment failure that wasn’t flagged in time.
Real-time data pipelines built on streaming data processing frameworks enable immediate responses to changing conditions. The tradeoff is infrastructure complexity and cost: real-time systems typically require 2–5x the investment of equivalent batch architectures, along with specialized engineering expertise to build and maintain.
Manual Processing: Human-Driven Validation
Manual processing applies where automated systems reach their limits — regulatory edge cases, unstructured data requiring domain interpretation, exception handling, and compliance scenarios where human oversight is a requirement rather than a fallback.
It offers contextual judgment that automation cannot replicate, but it doesn’t scale. Manual methods belong at the edges of a data architecture, not at the center.
How to Choose
| Processing Type | Best For | Key Tradeoff |
| Batch | Scheduled analytics, historical analysis, & cost-sensitive workloads | Latency |
| Real-Time | Fraud detection, personalization, & operational monitoring | Cost and complexity |
| Manual | Exception handling, compliance review, & unstructured data | Scale and speed |
The right choice depends on how quickly a decision needs to be made — and what the cost of a delayed response actually is.
The Three Layers of a Real-Time Data Processing Architecture
A production-ready real-time system isn’t a single tool. It’s a layered architecture where each component handles a distinct function. Understanding how the layers interact is useful for anyone evaluating build vs. buy decisions or assessing integration complexity.
Layer 1 – Ingestion: Capturing and Moving Data
The ingestion layer captures data at the source and moves it across distributed systems with minimal latency. Apache Kafka is the standard infrastructure for this function – a distributed message queue that handles clicks, transactions, sensor readings, and log events at scale, moving data in milliseconds without creating bottlenecks.
Kafka streaming architecture also addresses a persistent problem in enterprise data environments: silos. By establishing unified real-time data pipelines that multiple systems can read from, Kafka allows fraud detection, pricing engines, and analytics dashboards to operate from the same data stream simultaneously.
Layer 2 – Stream Processing: Transforming Data in Motion
The stream processing layer applies business logic to data as it moves through the pipeline — before it reaches storage. Frameworks like Apache Flink, Spark Streaming, and Amazon Kinesis handle aggregation, filtering, enrichment, and complex event detection in real time.
This is where raw data becomes actionable. A transaction flagged by an anomaly rule, a customer segment updated mid-session, a quality metric that triggers a production adjustment — all of these happen at the stream processing layer, not after the fact.
Layer 3 – Real-Time Analytics Databases: Storing and Serving Results
Specialized databases designed for high-speed reads and writes complete the architecture. These systems store processed streaming data while supporting instant queries — so dashboards reflect current conditions rather than the last time a batch job ran.
The balance between write throughput and query performance is the defining characteristic of this layer. When it’s calibrated correctly, business users get live visibility into operational metrics without placing additional load on upstream processing systems.
Five Trends Shaping the Future of Real-Time Data Processing
The core architecture of real-time systems is established. What’s changing is how that architecture is being extended, automated, and distributed. These five trends are worth tracking for any enterprise making infrastructure decisions in the next 12–24 months.
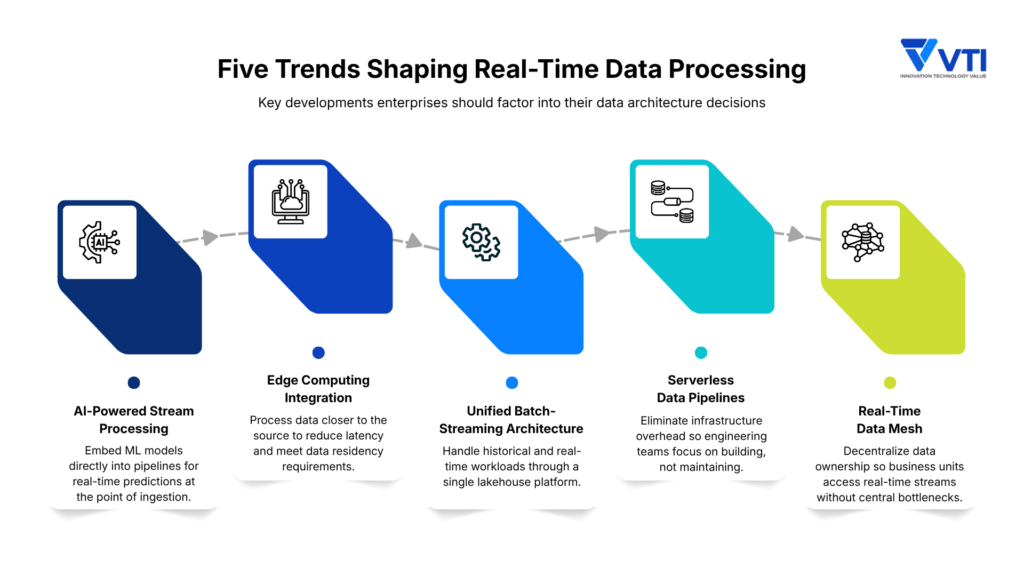
1. AI-Powered Stream Processing
Machine learning models are moving closer to the data pipeline itself. Rather than running inference on stored data after the fact, organizations are embedding models directly into stream processing layers — enabling real-time predictions, anomaly scoring, and classification at the point of ingestion.
For industries like finance and manufacturing, where millisecond-level decisions carry direct operational consequences, this integration is becoming a design requirement rather than an enhancement.
2. Edge Computing Integration
Processing is shifting toward the source. Edge computing reduces latency for applications where sending data to a central cloud environment introduces unacceptable delay — industrial sensors, connected vehicles, and 5G-enabled infrastructure being the clearest examples.
For enterprises operating in markets with data residency regulations, edge processing also addresses compliance requirements by keeping data local before it moves upstream.
3. Unified Batch-Streaming Architectures
The operational separation between batch and streaming systems has been a persistent source of complexity and cost. Open lakehouse platforms are consolidating both workloads into a single architecture — one that handles historical analysis and real-time processing without requiring separate pipelines or engineering teams.
By 2029, 75% of AI and data workloads are projected to move off legacy platforms, with unified architectures as the primary destination.
4. Serverless Data Pipelines
Serverless infrastructure removes the operational burden of provisioning and maintaining the systems that run streaming data processing workflows. Engineering capacity shifts toward building and refining pipelines rather than managing the infrastructure beneath them.
For organizations scaling real-time capabilities without proportional headcount growth, serverless pipelines offer a meaningful path to doing more with existing teams.
5. Real-Time Data Mesh
Centralized data teams create bottlenecks. Data mesh architectures address this by distributing ownership — giving business units direct access to real-time data streams without routing requests through a central function.
By 2027, 45% of APAC organizations are expected to adopt unified data management frameworks that support this kind of decentralized, domain-driven access — accelerating AI-driven insights at the business unit level rather than waiting for enterprise-wide rollouts.
Getting Started With Real-Time Data Processing
Real-time data processing is no longer a capability reserved for organizations with the largest engineering budgets. The infrastructure has matured, the tooling is more accessible, and the business case is well-established across finance, manufacturing, retail, and AI-driven applications.
The practical starting point is not a full architecture overhaul. It’s identifying where a delay in data — whether hours or minutes — is creating a measurable cost: fraud that clears before detection, inventory decisions made on yesterday’s stock levels, customer interactions missing context that was available seconds earlier.
Those gaps are where the return on real-time investment is clearest and fastest to demonstrate.
VTI works with enterprises across the region on data architecture assessments and production deployment of real-time pipelines. If your organization is evaluating where real-time processing fits in your data strategy, speak with our AI team.




